腾讯云授权服务中心
五万用户的选择,您身边的云计算顾问
 发布日:2022-01-13 10:12
发布日:2022-01-13 10:12
 阅读数:
阅读数:
首先得知道数据是什么?数据是对客观事务的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号总称。那为何加上“结构”两字?
数据元素是数据的基本单位,而任何问题中,数据元素都不是独立存在的,它们之间总是存在着某种关系,这种数据元素之间的关系我们称之为结构。
因此,我们有了以下定义:
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
简单讲,数据结构就是组织,管理以及存储数据的方式。虽然理论上所有的数据都可以混杂,或者糅合,或者饥不择食,随便存储,但是计算机是追求高效的,如果我们能了解数据结构,找到较为适合当前问题场景的数据结构,将数据之间的关系表现在存储上,计算的时候可以较为高效的利用适配的算法,那么程序的运行效率肯定也会有所提高。
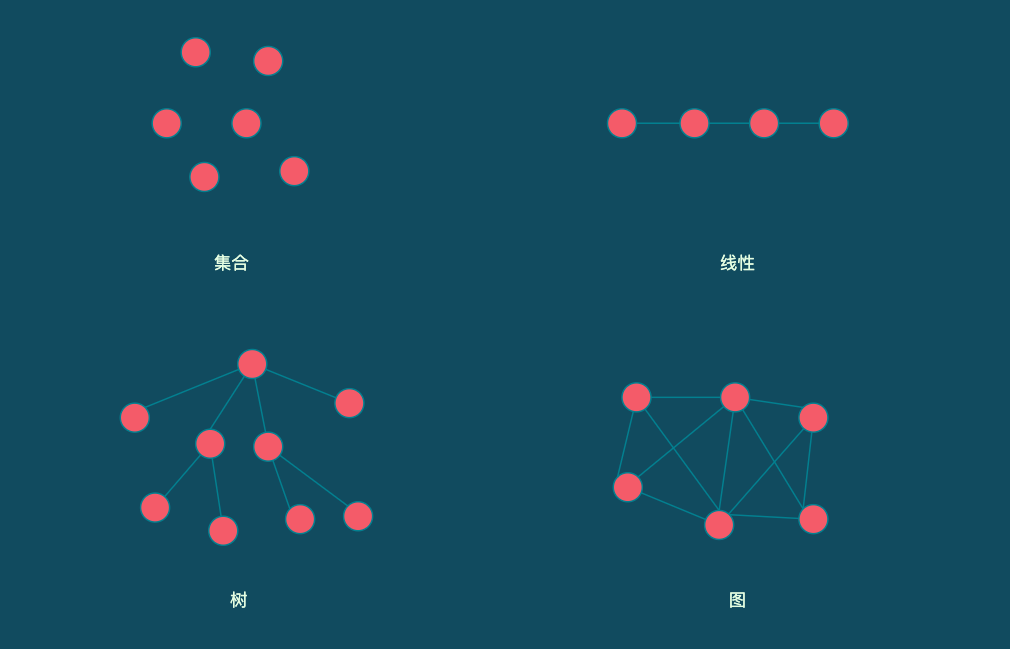
常用的4种数据结构有:
集合:只有同属于一个集合的关系,没有其他关系
线性结构:结构中的数据元素之间存在一个对一个的关系
树形结构:结构中的数据元素之间存在一个对多个的关系
图状结构或者网状结构:图状结构或者网状结构
在计算机中表示信息的最小的单位是二进制数中的一位,叫做位。也就是我们常见的类似01010101010这种数据,计算机的底层就是各种晶体管,电路板,所以不管是什么数据,即使是图片,声音,在最底层也是0和1,如果有八条电路,那么每条电路有自己的闭合状态,有8个2相乘,2^8^,也就是256种不同的信号。
00100011 35
+ 11011101 -35
-------------------------
00000000 0
00100011 35
+ 11011011 -37
-------------------------
11111110 -2
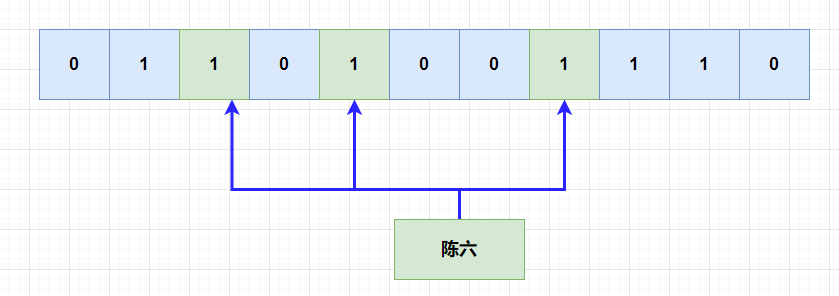
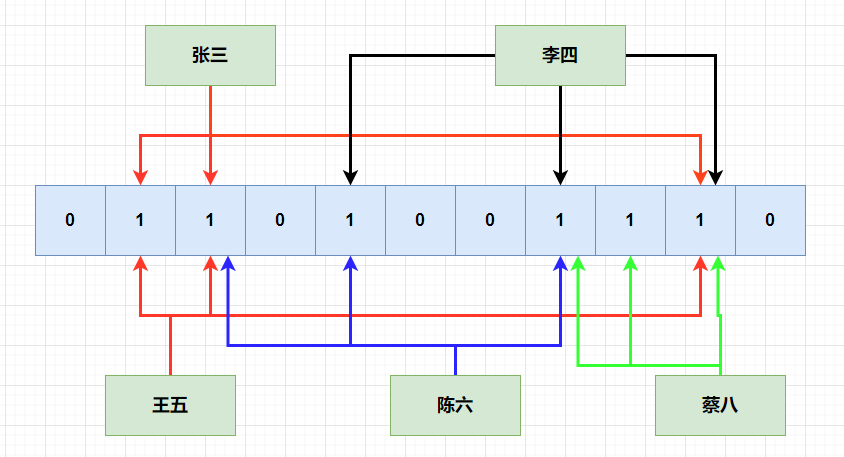
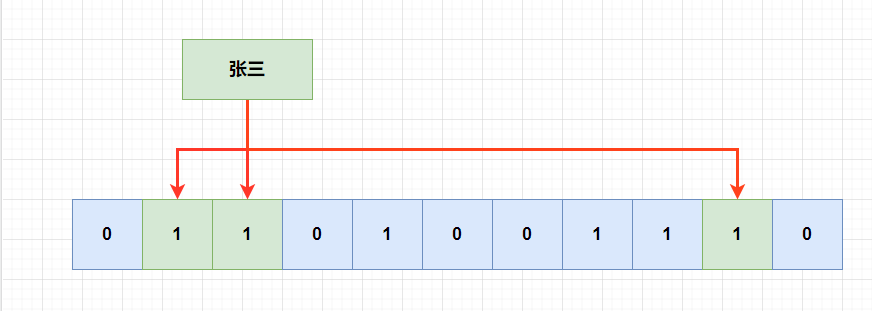
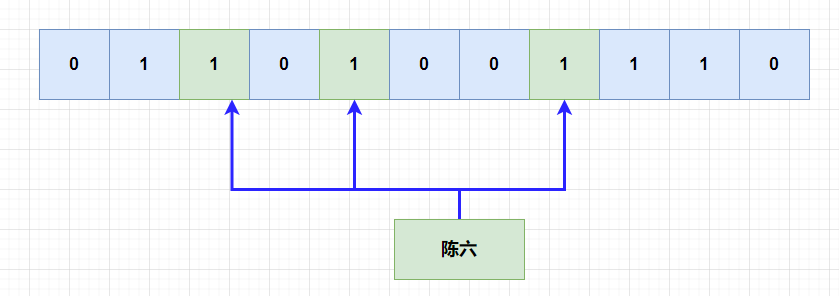
也就是当一个元素被加入集合的时候,通过多个hash函数,将元素映射到位数组中的k个点,置为1。
重点是多个hash函数,可以将数据hash到不同的位上,也只有这些位全部为1的时候,我们才能判断该数据已经存在
也是由于会出现多个元素可能hash到一起,但有一个数据被踢出了集合,我们想把它映射的位,置为0,相当于删除该数据。这个时候,就会影响到其他的元素,可能会把别的元素映射的位,置为了0。这也就是为什么布隆过滤器不能删除的原因。
编辑:航网科技 来源:腾讯云
本文版权归原作者所有 转载请注明出处
联系我们

0755-36300002
深圳市龙华区和平路龙胜商业大厦5楼B5区
资质证书




Copyright © 2011-2020 www.hangw.com. All Rights Reserved 深圳航网科技有限公司 版权所有 增值电信业务经营许可证:粤B2-20201122 - 粤ICP备14085080号
微信扫一扫咨询客服
全国免费服务热线
0755-36300002