腾讯云授权服务中心
五万用户的选择,您身边的云计算顾问
 发布日:2021-08-04 20:36
发布日:2021-08-04 20:36
 阅读数:
阅读数:
标准运维V3是通过可视化的图形界面进行任务流程编排和执行的系统,是腾讯蓝鲸产品体系中一款轻量级的调度编排类SaaS产品。基于腾讯蓝鲸PaaS平台的API网关服务,对接企业内部各个系统 API的能力, 将在多系统间切换的工作模式整合到一个流程中,实现一键自动化调度。
用户所编排的流程由标准运维底层使用的 bamboo-pipeline 流程引擎来进行调度和推进,在多年多种场景的使用下,引擎自身设计上的一些问题也暴露了出来,为了能为用户提供更好的服务,让标准运维走的更远,我们决定对底层流程引擎进行一次重构和升级。
旧版本的 bamboo-pipeline 引擎在设计和实现上存在下面这些问题:
bamboo-pipeline 在生成引擎执行数据后,会将整个流程对象序列化后存储到数据库中
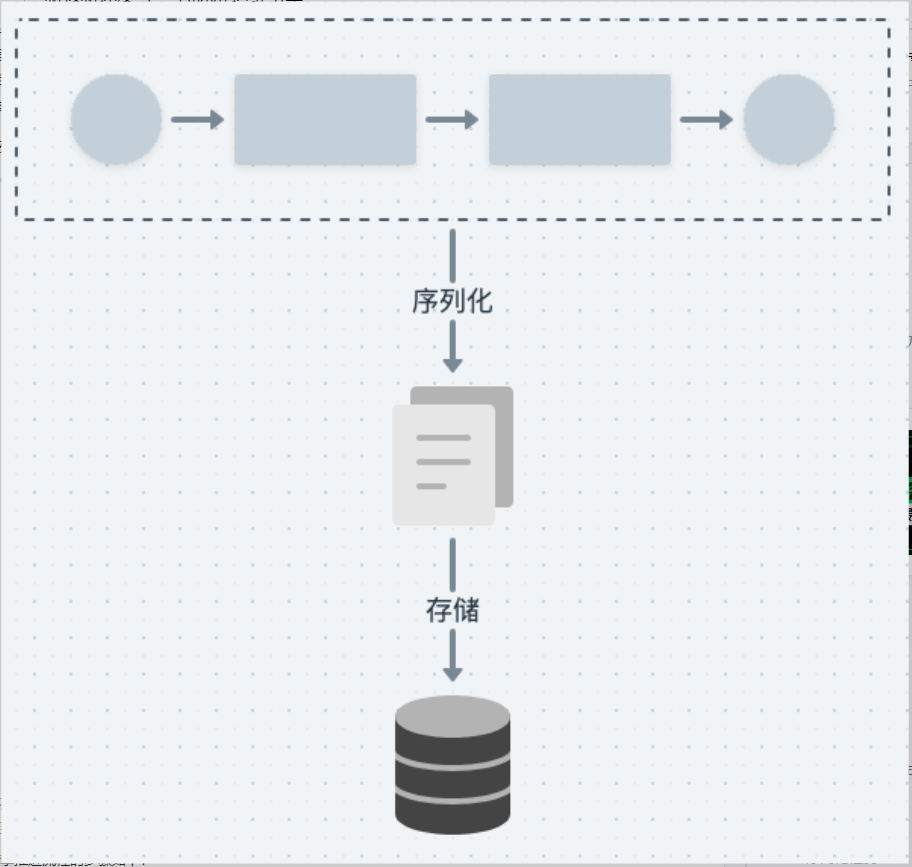
这种序列化粒度过于粗暴,对于小型流程(节点数量较少)来说,并不会产生特别大的问题。但是在处理大流程时(节点数量到达百,千级别),问题就会暴露出来。
因为引擎推进流程的步骤如下:
因为流程数据序列化粒度是整个流程,所以在第一步时就需要把所有的流程数据读取出来,即便当前流程只会继续往前推进1个节点,也需要读取整个流程的数据,导致引擎进行调度切换时的开销会很大。
bamboo-pipeline 使用 pickle 来进行流程执行数据的序列化,而 pickle 是 python 内置的一种二进制序列化方式,协议会随着 python 的升级发生变化,bamboo-pipeline 在当时进行 python2 升级 python3 时就处理过 pickle 协议升级和 python 内置对象升级导致的旧数据反序列化失败问题。
而且 pickle 序列化后的数据不可读,使得问题排查的成本大幅增加。
流程在执行过程中节点会产生执行数据,这些数据也是需要持久化存储的。bamboo-pipeline 将执行数据和流程对象一起存储到数据库中,这就导致节点输出数据增长时会导致流程执行数据膨胀,增加引擎进行调度切换时的开销。
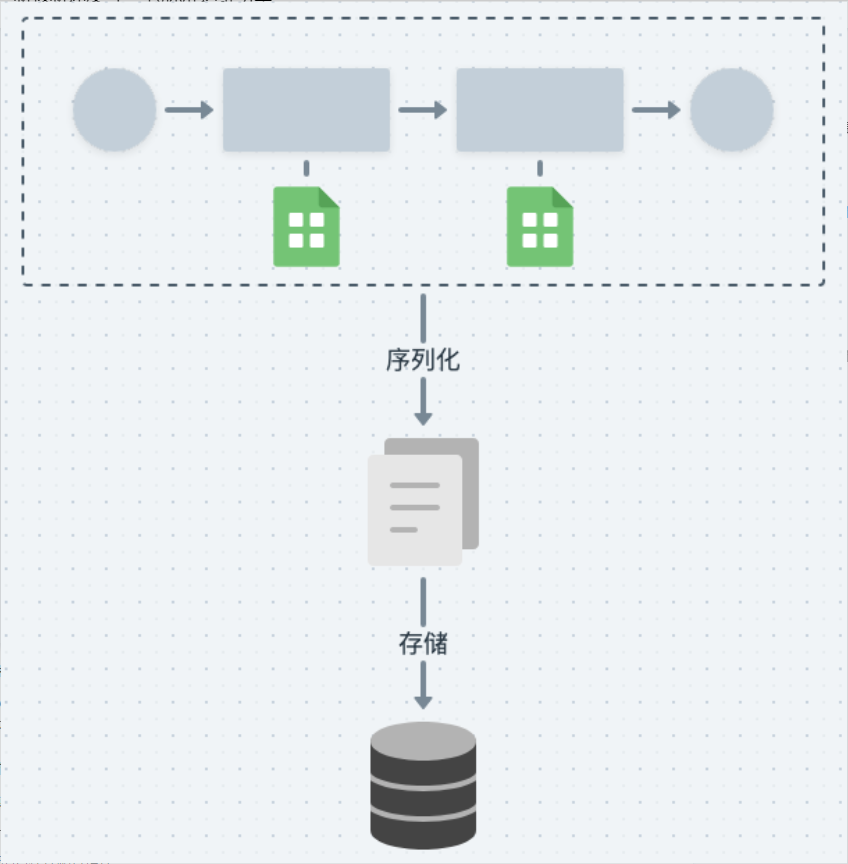
bamboo-pipeline 没有将引擎的控制面与执行面进行分层,导致整个流程引擎 SDK 与特定框架(Django,Celery)产生了强耦合,不利于后续引擎的升级和新功能的开发,用户的使用成本也比较高。
为了解决上述这些问题,我们进行了新版本引擎 bamboo-engine 的设计和实现,目标如下:
针对上一节提到的各种问题,新引擎的解决方案如下
bamboo-engine 采用了更细粒度的方式来进行序列化,将流程中每个节点的数据拆分存储,这样,能够保证引擎能够以最小单元(单个节点)来进行读取,减少调度切换时不必要的开销,提升引擎的调度效率。
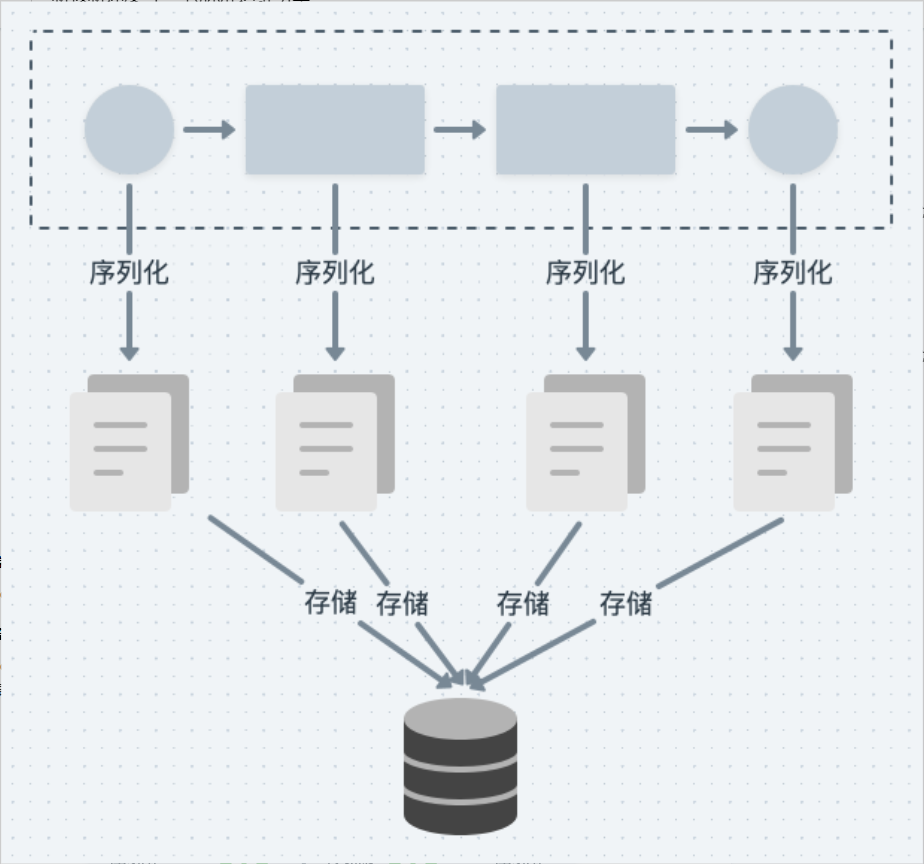
bamboo-engine 采用 JSON 格式进行序列化,摆脱了对 pickle 的依赖,降低后续引擎版本升级,问题排查的成本。
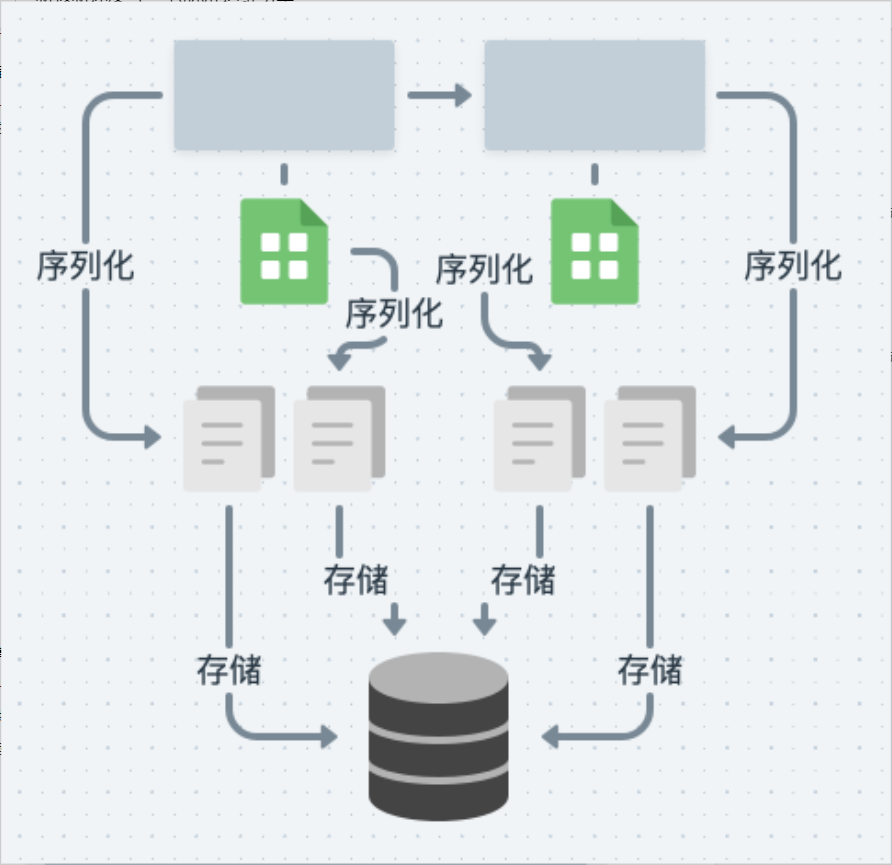
bamboo-engine 除了将每个节点的数据拆分存储外,同时也会单独对节点执行的数据进行存储。保证流程静态数据和动态数据的存储分离,同时即便节点输出了比较大的执行数据,也不会影响后续流程的执行效率。
bamboo-engine 由 引擎 与 运行时接口 两个部分构成。
引擎模块负责实现流程的核心调度逻辑,即流程的推进逻辑、每种类型节点的处理逻辑、流程的调度切换逻辑等。
实现了运行时接口的引擎运行时向引擎提供流程运行时数据存储、流程进程管理、任务派发的实现,两者的关系如下图所示:
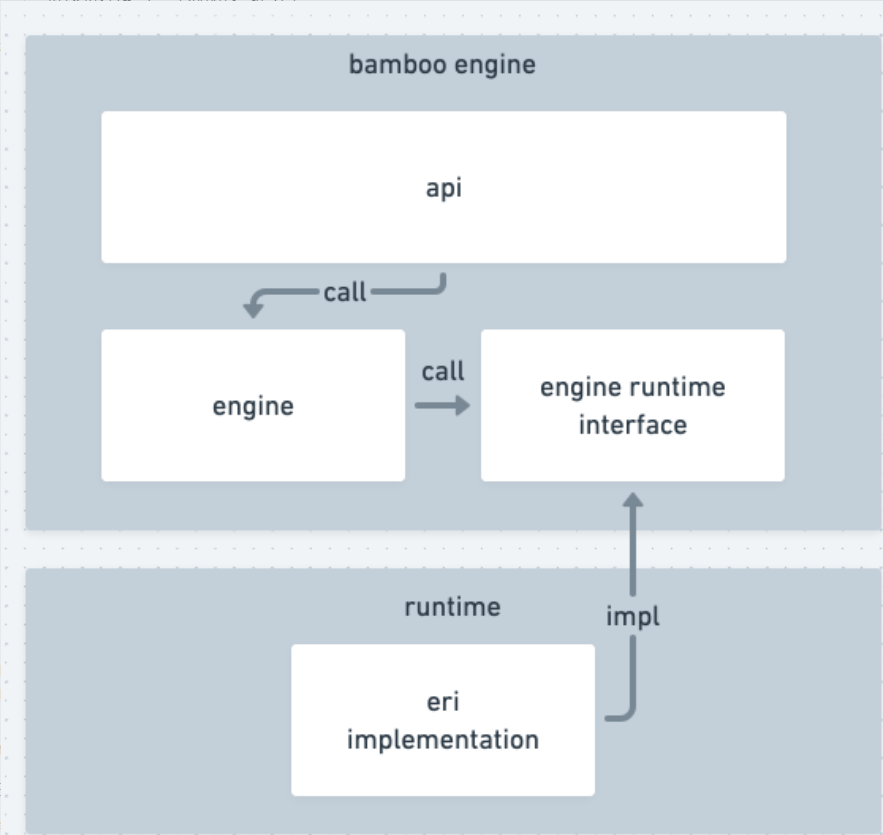
将运行时抽象出来的好处是,如果默认提供的运行时在某些方面无法满足项目的需求,可以根据运行时接口实现一套新的运行时,便能直接集成到引擎中。
同时,为了增加系统的可观测性,bamboo-engine 会记录核心度量指标并提供采集入口,以供接入蓝鲸监控、Prometheus 等监控系统。
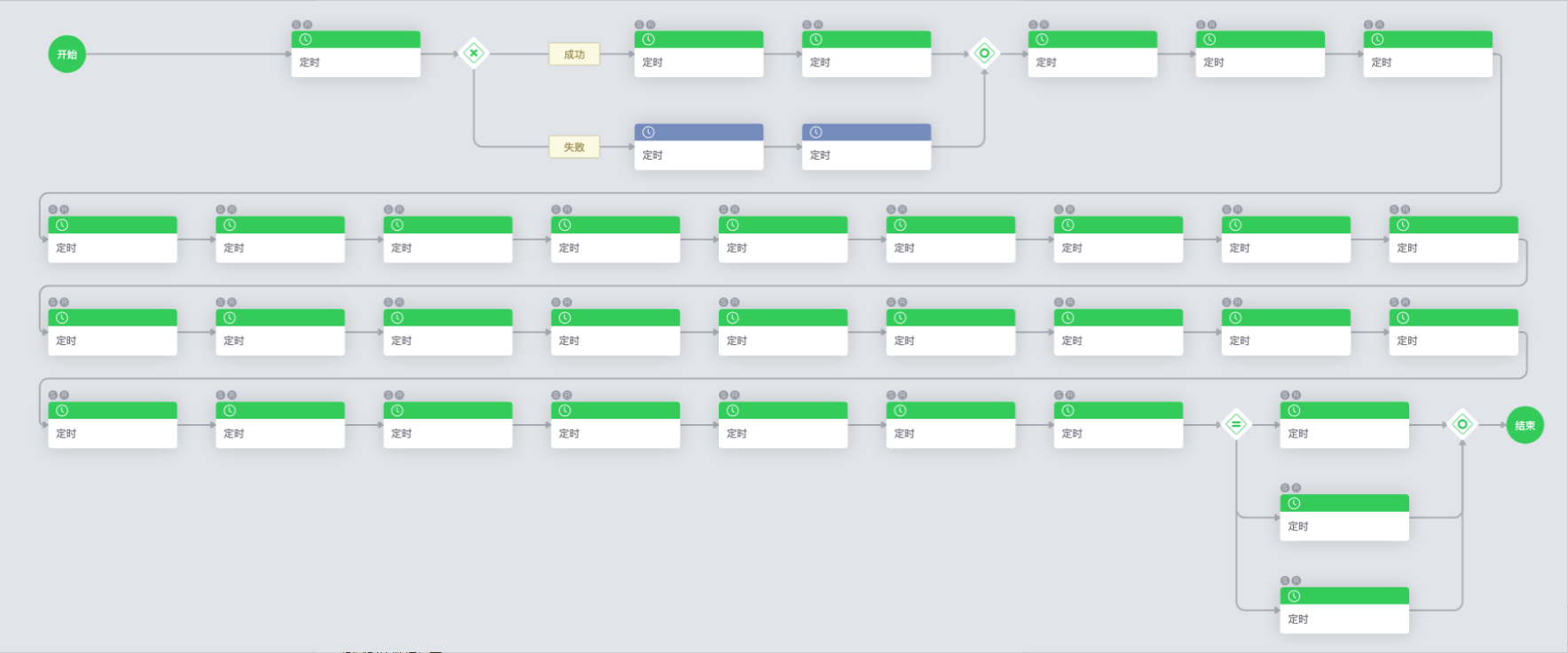
标准运维在完成新引擎的升级后,我们进行了一次对比测试,测试使用的流程如下:
测试环境为
MacBook Pro(16 英寸,2019) 处理器:2.6 GHz 六核Intel Core i7 内存:32 GB 2667 MHz DDR4 OS:macOS Big Sur 11.2.1 Broker:RabbitMQ 3.8.2 engine worker 以 gevent 模式启动,100 并发
测试过程:分别在新旧两套引擎上同时创建并启动100个测试流程,测量以下指标:
流程执行耗时 - 调度切换耗时)最后一个完成的流程完成时间 - 第一开始的流程开始时间)
测试对比数据如下:
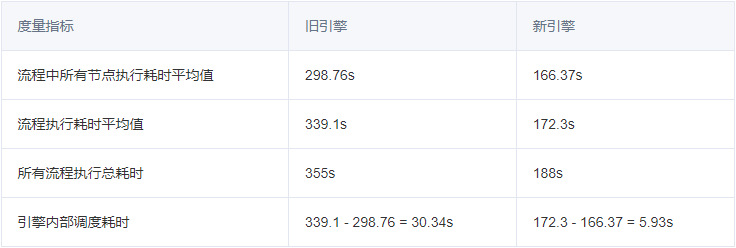
可以看到,新引擎的吞吐量对比旧引擎提升了一倍,同时,引擎内部调度耗时也明显减少,可以看出,这次的升级是有效并且值得的。
新引擎的地址:https://github.com/Tencent/bk-sops/tree/sdk/sdk/bamboo-engine
编辑:航网科技 来源:腾讯云
本文版权归原作者所有 转载请注明出处
联系我们

客服部:深圳市龙华区龙胜商业大厦5楼B5区
业务部:深圳市南山区讯美科技广场2栋12楼1202
资质证书




Copyright © 2011-2020 www.hangw.com. All Rights Reserved 深圳航网科技有限公司 版权所有 增值电信业务经营许可证:粤B2-20201122 - 粤ICP备14085080号
微信扫一扫咨询客服
全国免费服务热线
0755-36300002