腾讯云授权服务中心
五万用户的选择,您身边的云计算顾问
 发布日:2022-02-07 14:50
发布日:2022-02-07 14:50
 阅读数:
阅读数:
MDP由四元组构成, M=(S,A,P,R)
S: 表示状态集,其中 Si 表示第i个时刻的状态,s∈S
A:表示动作集,其中 ai 表示第i个时刻的动作, a∈A
P:表示转移概率。 Psa 表示从状态s执行动作a后,转移到另一个状态的概率。
R:表示回报函数。从状态s执行动作a。注意这里的回报是立即回报。其中从S状态到A动作的映射,就是行为策略,记为策略π:S→A。
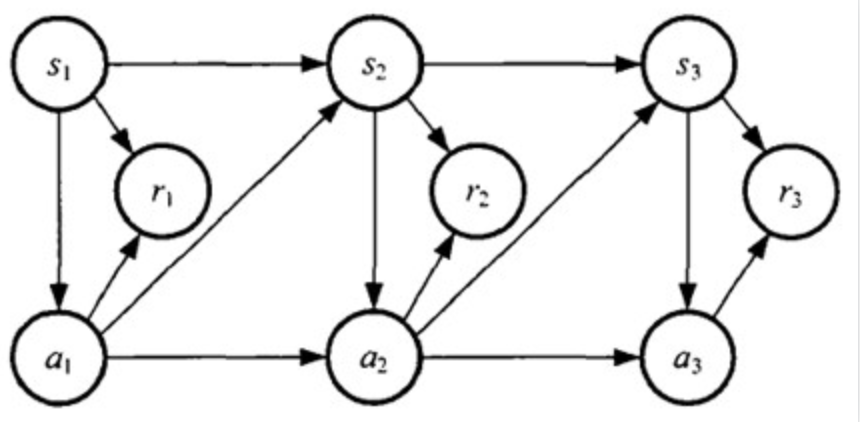
MDP 的动态过程如下图:智能体从状态s1,采用动作a1,进入状态s2,同时得到回报r1。然后从状态s2采取动作a2进入状态s3,得到回报r2....
其中γ∈(0,1)称为折合因子,表明了未来的回报相对于当前回报的重要程度。γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。
价值函数 V(s)定义为状态S的长期价值,即 Gt 的数学期望
然后再考虑MDP过程还有一个策略和动作,给定策略π和初始状态s,则动作a=π(s),我们就可以定义
状态值函数:
动作值函数(给定当前状态s和当前动作a,在未来遵循策略π):
在qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是qπ(s,a)和Vπ(s)的主要区别。
一个MDP的最优策略就是最优状态-价值函数:v∗(s)=maxπvπ(s) 状态s下,选择一个能使价值最大的策略。
上面提到我们的目的是找到一个让值函数最大的策略,求一个最优解问题。
主要使用的方法有:
动态规划方法(DP)计算值函数:
通过公式看出DP计算值函数用到了当前状态s的所有s′处的值函数,也就是bootstapping方法(用后继状态的值函数估计当前值函数)。而后继状态是用模型 p(s′,r|St,a) 计算得到的。
所以DP是存储每个状态的值函数Q表,根据Q表通过迭代方法得到最佳的策略。存储Q表后,利用后续状态值函数估计当前值函数,可以实现单步更新,提升学习效率。
优势:提前得到Q表后,不需要再与环境交互,直接通过迭代算法得到最佳策略。
劣势:实际应用中,状态转移概率和值函数是很难得到的
蒙特卡罗方法(MC),它的状态值函数更新公式为:
其中Gt是每个探索结束后得到的累计回报,α为学习率。我们用St的累计回报Gt和当前估计V(St)的偏差值乘以学习率来更新当前的V(St)的新的估计值。因为没有模型得到状态转移概率,所以MC是用经验平均值估计状态的值函数。
蒙特卡罗方法是通过采样的方法(试错,和环境进行交互)来估计状态的期望值函数。采样之后,环境给出奖励信息,体现在值函数中。
优势:不需要知道状态转移概率,而是通过经验(采样和试错实验)去评估期望值函数,只要采样的次数足够多,保证每个可能的状态-动作都能采样到,就可以最大程度的逼近期望。
劣势:由于值函数是要从状态s到最终状态累计奖励,所以每次实验都必须执行到终态才能得到状态s的值函数,学习效率很低。
最后看时间差分法(TD)算法的值函数更新公式:
其中rt+1+γV(St+1) 和MC中的Gt对应,不需要使用状态转移函数的模型,同时它不需要执行到终态得到累计回报,而是使用下一个时刻的即刻回报和值函数,类似DP的bootstapping方法。
编辑:航网科技 来源:腾讯云
本文版权归原作者所有 转载请注明出处
联系我们

客服部:深圳市龙华区龙胜商业大厦5楼B5区
业务部:深圳市南山区讯美科技广场2栋12楼1202
资质证书




Copyright © 2011-2020 www.hangw.com. All Rights Reserved 深圳航网科技有限公司 版权所有 增值电信业务经营许可证:粤B2-20201122 - 粤ICP备14085080号
微信扫一扫咨询客服
全国免费服务热线
0755-36300002