腾讯云授权服务中心
五万用户的选择,您身边的云计算顾问
 发布日:2022-02-08 15:33
发布日:2022-02-08 15:33
 阅读数:
阅读数:
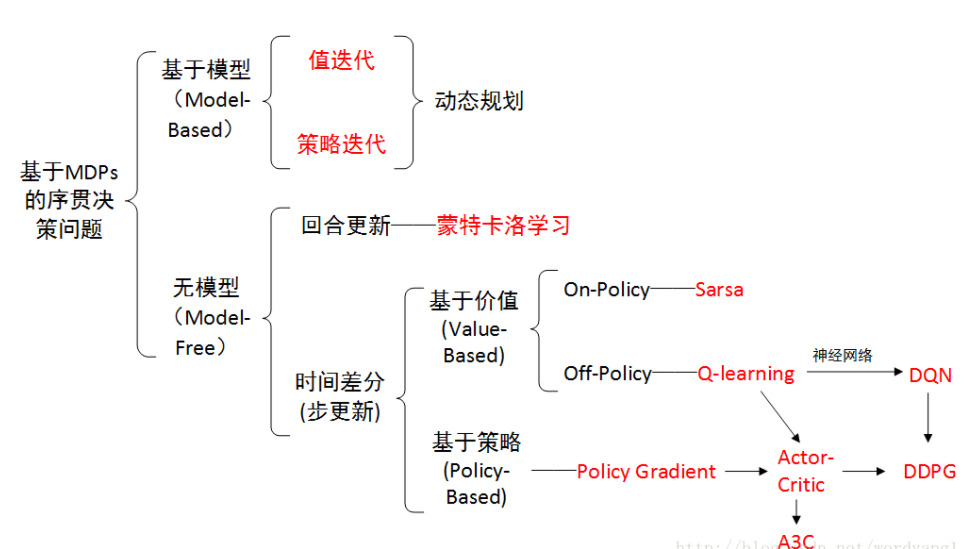
SARSA算法的基础思路就是他的名字(State-Action-Reward-State'-Action')。先基于 ϵ -贪婪法对当前状态S选择动作A,进入下一个状态S′并得到即时回报R,在新状态S′下再基于 ϵ -贪婪法选择下一个动作A′,更新价值函数:
如此循环迭代,直到收敛。
(其中 ϵ -贪婪法指设置一个小的ϵ值,1−ϵ的概率选择目前认为是最大行为价值的行为, ϵ的概率从动作空间中选择动作)
Q-learning的基本思路是先基于 ϵ-贪婪法对当前状态S选择动作A, 进入下一个状态S′并得到即时回报R,(这里和SARSA一样),接下来使用贪婪法选择A′来更新价值函数(SARSA是使用ϵ -贪婪法选择A′去更新价值函数)
价值函数更新后,新的动作是基于状态S′,用 ϵ -贪婪法重新得到。(SARSA是直接使用A’作为下一步开始执行动作)
SARSA和Q-learning都是价值迭代,通过价值函数的更新来更新当前策略,然后通过策略得到新的状态和即时奖励,循环迭代直到价值函数和策略收敛,得到最优价值函数和最优策略。
对于价值函数我们也可以通过神经网络来进行近似表示。对于状态价值函数,输入是状态s,输出是状态价值V(s,w)。对于动作价值函数,一种是输入状态s和动作a,输出对于动作价值q(s,a,w),一种是只输入状态s,动作集合有多少个动作就有多少个q(s,ai,w)。
,给定状态s,得到选择的动作a的概率。
在基于值的方法中,选择动作的策略是不变的,使用贪婪选择法,而在基于策略中是通过概率分布选择的。
首先它是可以处理离线动作空间的,从s输出一个离散分布,选择每个动作的概率;其次,对于连续空间,可以先假设动作服从一个分布,然后从s输出一个动作的均值,选择动作时就可以利用分布选择。
在基于价值算法中,是根据值函数对策略进行改进,对比基于策略的方法,他的决策更为肯定就是选择价值最高的;而基于策略方法,是直接对策略进行迭代,直到累计回报最大。
编辑:航网科技 来源:腾讯云
本文版权归原作者所有 转载请注明出处
联系我们

客服部:深圳市龙华区龙胜商业大厦5楼B5区
业务部:深圳市南山区讯美科技广场2栋12楼1202
资质证书




Copyright © 2011-2020 www.hangw.com. All Rights Reserved 深圳航网科技有限公司 版权所有 增值电信业务经营许可证:粤B2-20201122 - 粤ICP备14085080号
微信扫一扫咨询客服
全国免费服务热线
0755-36300002