腾讯云授权服务中心
五万用户的选择,您身边的云计算顾问
 发布日:2022-02-09 15:13
发布日:2022-02-09 15:13
 阅读数:
阅读数:
conda create -n gym pip install gym pip install pyglet
#!/usr/bin/env python # -*- coding: utf-8 -*- import gym env = gym.make('CartPole-v0') env.reset() for _ in range(1000): env.render() # take a random action env.step(env.action_space.sample()) env.close()
print("env.action_space", env.action_space) >> Discrete(2)
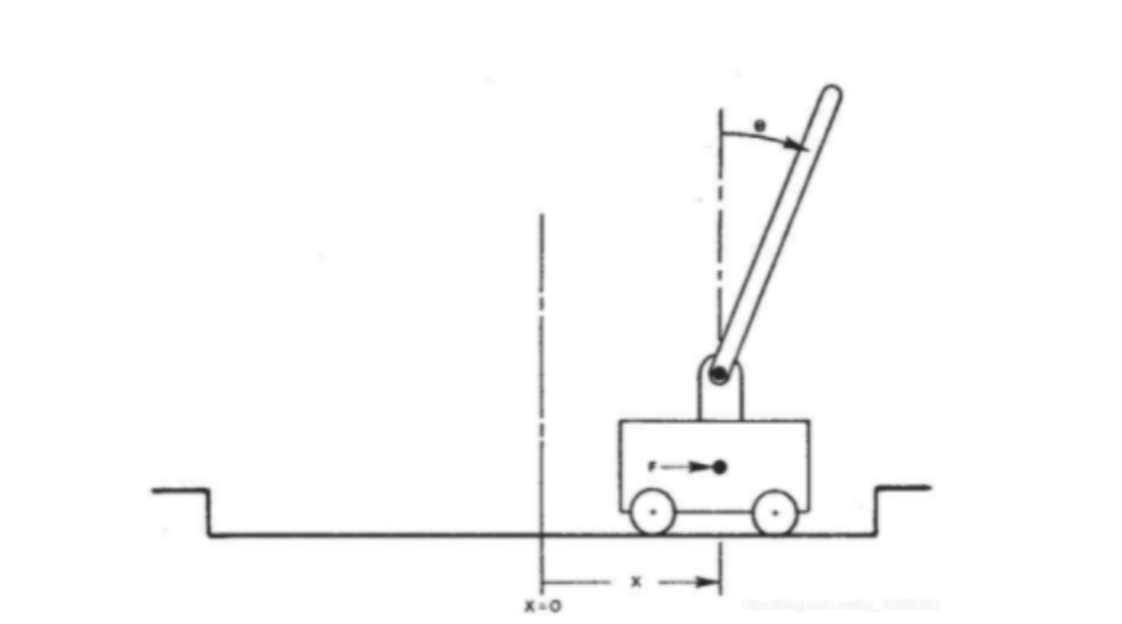
动作空间是一个离散数据: 状态空间值{0,1},0--表示左移动,1--表示右移动
print("env.observation_space", env.observation_space) >>Box(4,)
import gym # 创建一个CartPole-v0(小车倒立摆模型) env = gym.make('CartPole-v0') for i_episode in range(1000): # 环境重置,得到一个初始observation observation = env.reset() for t in range(1000): # 渲染引擎显示物体状态 env.render() # 动作空间,{0,1} 0-左移动, 1-右移动 print("env.action_space", env.action_space) # >>Discrete(2) 一个离散空间 # 状态空间 print("env.observation_space", env.observation_space) # >>Box(4,) 多维空间 # 奖励范围和状态空间范围 # print("env.reward_range", env.reward_range) # print("env.observation_space.high", env.observation_space.high) # print("env.observation_space.low", env.observation_space.low) # print("env.observation_space.bounded_above", env.observation_space.bounded_above) # print("env.observation_space.bounded_below", env.observation_space.bounded_below) # 随机选取动作 sample_action = env.action_space.sample() """ observation:当前观察的object的状态值 小车在轨道上的位置,杆子和竖直方向的夹角,小车速度,角度变化率) reward: 执行上一个action后的奖,每一步给出奖励1 done:本轮探索是否结束,是否需要reset环境 达到下列条件之一片段结束: 杆子与竖直方向角度超过12度 小车位置距离中心超过2.4(小车中心超出画面) 考虑片段长度超过200 考虑连续100次尝试的平均奖励大于等于195。 info:调试信息 """ observation, reward, done, info = env.step(sample_action) print('observation:{}, reward:{}, done:{}, info:{}'.format(observation, reward, done, info)) # 如果结束, 则退出循环 if done: print("Episode finished after {} timesteps".format(t + 1)) break env.close()
import numpy as np import gym import time def get_action(weights, observation): """ 根据weights,对observation进行加权求和,根据值决定动作策略 """ wxb = np.dot(weights[:4], observation) + weights[4] if wxb >= 0: return 1 else: return 0 def get_sum_reward_by_weights(env, weights): """ 根据当前策略,计算本次探索的累计reward """ observation = env.reset() sum_reward = 0 for t in range(1000): # time.sleep(0.01) # env.render() action = get_action(weights, observation) observation, reward, done, info = env.step(action) sum_reward += reward if done: break return sum_reward def get_weights_by_random_guess(): """ 使用 Random Guessing Algorithm 返回weights, 没轮随机给出权重 """ return np.random.rand(5) def get_weights_by_hill_climbing(best_weights): """ 使用 hill_climbing Algorithm 返回weights, 每次最好的权重加上一点随机变化 """ return best_weights + np.random.normal(0, 0.1, 5) def get_best_result(algo="random_guess"): env = gym.make("CartPole-v0") np.random.seed(10) best_reward = 0 best_weights = np.random.rand(5) # 进行100轮探索 for iter in range(10000): # 选择策略算法 if algo == "hill_climbing": cur_weights = get_weights_by_hill_climbing(best_weights) else: cur_weights = get_weights_by_random_guess() # 使用本轮探索得到的策略权重,得到累计reward cur_sum_reward = get_sum_reward_by_weights(env, cur_weights) # 保存探索过程中最好的reward对应的权重值 if cur_sum_reward > best_reward: best_reward = cur_sum_reward best_weights = cur_weights if best_reward >= 200: break print(iter, best_reward, best_weights) return best_reward, best_weights if __name__ == '__main__': get_best_result("hill_climbing")
编辑:航网科技 来源:腾讯云
本文版权归原作者所有 转载请注明出处
联系我们

客服部:深圳市龙华区龙胜商业大厦5楼B5区
业务部:深圳市南山区讯美科技广场2栋12楼1202
资质证书




Copyright © 2011-2020 www.hangw.com. All Rights Reserved 深圳航网科技有限公司 版权所有 增值电信业务经营许可证:粤B2-20201122 - 粤ICP备14085080号
微信扫一扫咨询客服
全国免费服务热线
0755-36300002