一个监控系统对于每一个服务和应用基本上都是必不可少的。在 Flink 源码中监控相关功能主要在 flink-metrics 模块中,用于对 Flink 应用进行性能度量。Flink 监控模块使用的是当前比较流行的 metrics-core 库,来自 Coda Hale 的 dropwizard/metrics [1]。dropwizard/metrics 不仅仅在 Flink 项目中使用到,Kafka、Spark 等项目也是用的这个库。Metrics 包含监控的指标(Metric)以及指标如何导出(Reporter)。Metric 为多层树形结构,Metric Group + Metric Name 构成了指标的唯一标识。Reporter 支持上报到 JMX、Influxdb、Prometheus 等时序数据库。Flink 监控模块具体的使用配置可以在 flink-core 模块的 org.apache.flink.configuration.MetricOptions 中找到。
指标类型
Flink 支持 Metrics 中的 Counters、 Gauges、 Histograms 和 Meters 四种类型指标。
Counter Counter 计数器用于计数。可以使用 inc()/inc(long n) 或 dec()/dec(long n) 来减小或减小当前值。可以通过在 MetricGroup 上调用 counter(String name) 来创建和注册计数器。 例如,Flink 算子的接收记录总数 (numRecordsIn) 和发送记录总数 (numRecordsOut) 就属于 Counter 类型。
Gauge Gauge 计量器根据需要提供任何类型的值。 使用 Gauge 可以通过在 MetricGroup 上调用 gauge(String name, Gauge gauge) 来注册 Gauge 计量器。例如,Status.JVM.Memory.Heap.Used 当前堆内存使用量就属于此类型。
Histogram Histogram 直方图(柱状图)用来统计数据的分布。您可以通过在 MetricGroup 上调用 histogram(String name, Histogram histogram) 来注册 Histogram 直方图。用于统计一些数据的分布,比如分位数(Quantile)、均值、标准偏差(StdDev)、最大值、最小值等,其中最重要一个是统计算子的延迟。此项指标会记录数据处理的延迟信息,对任务监控起到很重要的作用。
Meter Meter 计量器用来测量平均吞吐量或每个单位时间内出现的次数。 可以使用 markEvent() 方法注册事件的发生。 多个事件同时发生可以用 markEvent(long n) 方法注册。 您可以通过在 MetricGroup 上调用 meter(String name, Meter Meter) 来注册一个计量器。例如,记录每秒接收记录数(numRecordsInPerSecond)、每秒输出记录数(numRecordsOutPerSecond)属于 Meter 类型。
Scope 作用范围
Scope 包含用户域和系统域。Flink 的指标体系是按树形结构划分的,每个指标都用一个标识符来表示,标识符的会以“系统域.用户域.名称”的格式来命名。
常见指标类型
常见系统指标类型包含 CPU、内存、线程、垃圾回收、类加载、网络状况、Shuffle 相关、集群、Job 、可用性相关、Checkpoint、IO、Connectors、系统资源等指标。 End-to-End latency 端到端链路时延指标,默认关闭。将 metrics.latency.interval 参数值设为大于 0 时开启此设置。该指标的实现是采用了一个叫 LatencyMarker 带有时间戳的 StreamElement 。Flink 会周期性地触发 LatencyMarker,从 StreamSource 标记初始时间戳后通过各个算子传递到下游,每到一个算子时就会算出本地时间戳与 Source 生成时间戳的差值,当到达最后一个算子或 Sink 时即可得到端到端链路的时延。这个指标对 Flink 集群的性能影响很大,建议只在调试阶段使用。 State access latency 状态访问延迟指标,默认关闭。将 state.backend.latency-track.keyed-state-enabled 设为 true 开启此设置。状态访问延迟指标能够追踪 keyed state 访问延迟和任何继承自 AbstractStateBackend 的 State。
自定义 Metrics
那么如何根据上述指标类型来实现一个自定义的指标呢?我们需要在 Flink 应用中通过调用 getRuntimeContext().getMetricGroup() 从任何扩展实现 RichFunction 接口的 UDF 函数访问 Metric 系统。getMetricGroup 方法返回一个 MetricGroup 对象,我们在这个 MetricGroup 对象上创建和注册自定义指标。MetricRegistry 用于追踪所有注册了的 Metrics ,通过其实现类 MetricRegistryImpl 将 MetricGroup 和 MetricReporter 链接起来。 自定义 Metrics 示例:
Metrics 上报机制
Flink 的指标上报有两种方式:内置 Reporter 主动推送和 REST API 被动拉取。Flink 的 WebUI 中采用的是 REST API 的方式获取指标,我们可以通过 flink-rumtime 模块的 WebMonitorEndpoint 类可以查看到具体上报了哪些指标种类。
Metric Reporter 上报指标
Metric Reporter [1] 通过一个单线程的线程池定时调用 Scheduled 接口的实现类的 report 函数完成定时上报数据,默认每 10 秒上报一次。flink-metrics 模块中通过实现 MetricReporter 接口实现了对 Datadog、Graphite、Influxdb、JMX、Prometheus、Slf4j 日志、StatsD(网络守护进程)等日志模块和监控系统的支持。 以 Prometheus 为例,简单说明一下 Flink 是如何以主动推送方式上报监控指标的。
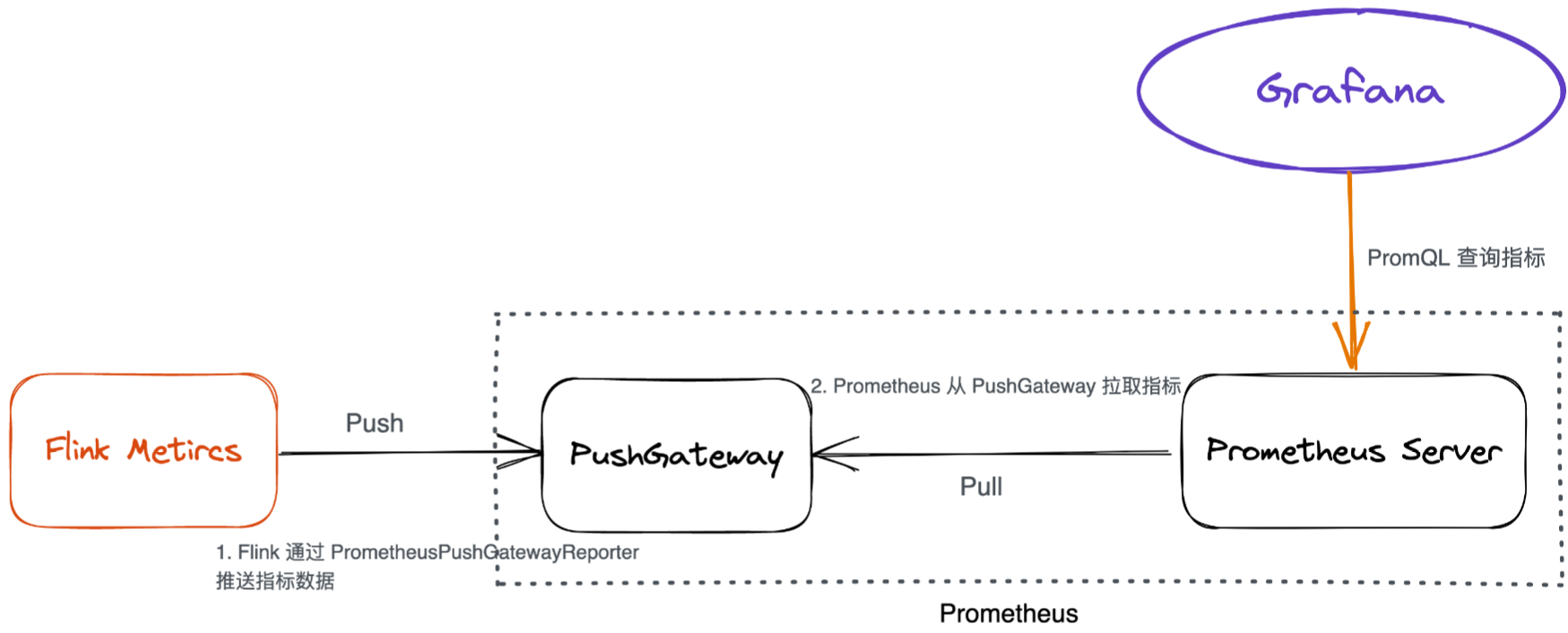
如需支持自定义 Reporter,例如 KafkaReporter,我们需要实现 MetricReporter、Scheduled接口并重写 report 方法即可。 MetricRegistry 是在 flink-rumtime 模块 ClusterEntrypoint 类 initializeServices 方法中完成了对 Reporters 的注册。
REST API 接口上报指标
REST API 则是通过提供 RESTful 接口返回集群、作业、算子等状态。使用 Netty 和 Netty Router 库来处理 REST 请求和转换 URL。 例如,用 Postman 等 REST 工具来获得 JobManager 的通用指标。
REST 支持的常见接口可参考下表,更多接口请参考 Flink 官方文档 REST API 调用 [3]。
|
|
|
|
|
|
/taskmanagers/<taskmanagerid>/metrics
|
|
|
|
|
/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtaskindex>
|
|
|
|
|
|
|
|
更多 Rest API 请参考 REST API 接口说明 [4]。
总结
Flink 支持的四种指标类型里,在累计计数时使用 Counter,一般当我们需要统计函数的调用频率(TPS)会用到 Meters,统计函数的执行耗时会用到 Histograms 直方图,统计 Java Heap 使用量等瞬时值或统计吞吐时用到 Gauge。当定位应用性能问题时,一般我们会先从业务维度上出发来判断问题的瓶颈。比如并行度是否合理、是否有背压、是否数据倾斜等;其次才是根据 Checkpoint 对齐(等待)、垃圾回收、State 存储等耗时来进一步分析;最后,再从系统指标中分析 CPU、网络 IO、磁盘 IO 等使用情况。腾讯云流计算 Oceanus [5] 平台是基于 Apache Flink 构建的企业级实时大数据分析平台,已经完整地支持了上述指标的配置,也支持自定义 Prometheus 的监控指标上报,还能够完成告警的实时提醒功能。如何实现实时告警,可参考文章 实时监控:基于流计算 Oceanus(Flink) 实现系统和应用级实时监控 [6]。腾讯云流计算 Oceanus 还提供了 1 元购 Flink 集群 [7]活动,欢迎大家购买体验。
 发布日:2022-04-10 14:08
发布日:2022-04-10 14:08
 阅读数:
阅读数:




